njtr1: An R package to download & analyze New Jersey car crash data

In this post I will introduce njtr1, my new R package that makes it easier to research road safety in New Jersey using open data released by the New Jersey Department of Transportation with a consistent and simple API, eliminating the manual drudgery currently inherent in working with these data.
You can install the package from the R console from CRAN by running install.packages('njtr1').
Making New Jersey’s crash data easier to analyze
When a motor vehicle crash is reported to law enforcement in New Jersey, the officers who respond to the scene are required to fill out a standard form, the NJTR-1. In addition to being part of the police report, the fields of data that are collected on this form are stored by the New Jersey Department of Transportation, which makes several tables of data available for statewide and county-by-county analysis.
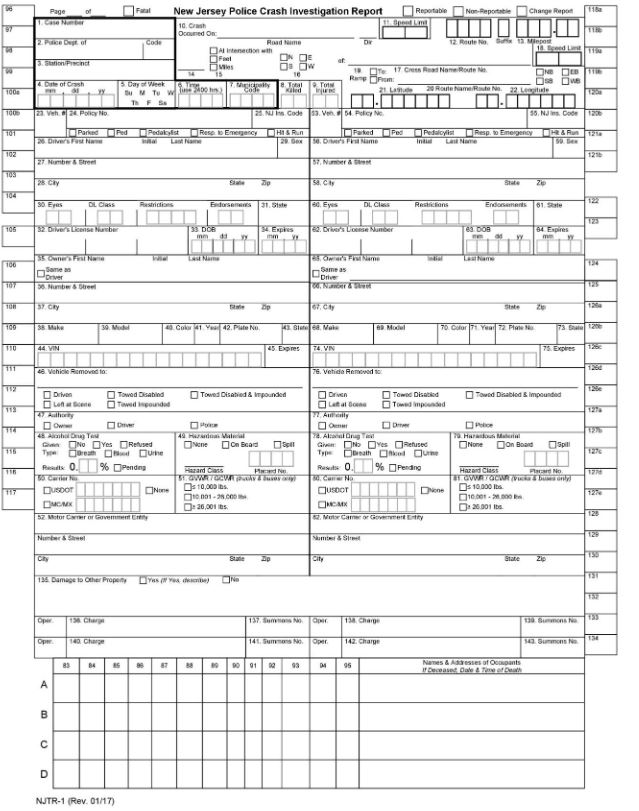
Unfortunately, the format and method that the NJDOT offers for accessing these data isn’t the most convenient. For one, the department only provides zipped .TXT files that do not contain any column names for each of the 5 tables of crash data that they make available.
The only column headers available from the department are PDF documents that would require you to manually input over 50 column names for each table or painstakingly look them up using the PDFs describing the schema on NJDOT’s website.
Who has the time to do that?
Attempting to manually read in a table in its original form produces the following ugly mess in RStudio:
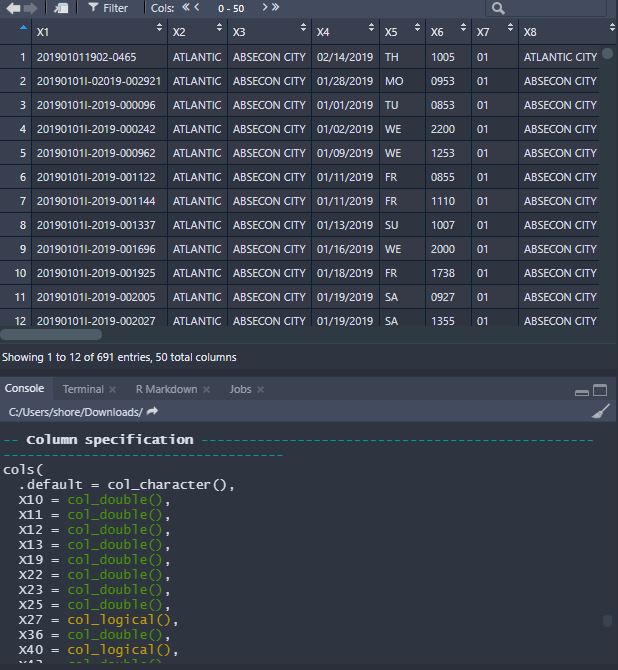
Secondly, if you want to study car crash data from multiple years or multiple tables, more friction is introduced by way of the design of the crash table download page on the NJDOT website. Instead of leveraging the state’s open data portal, or even providing direct links, one is forced to manully click dropdown menus to get this data:
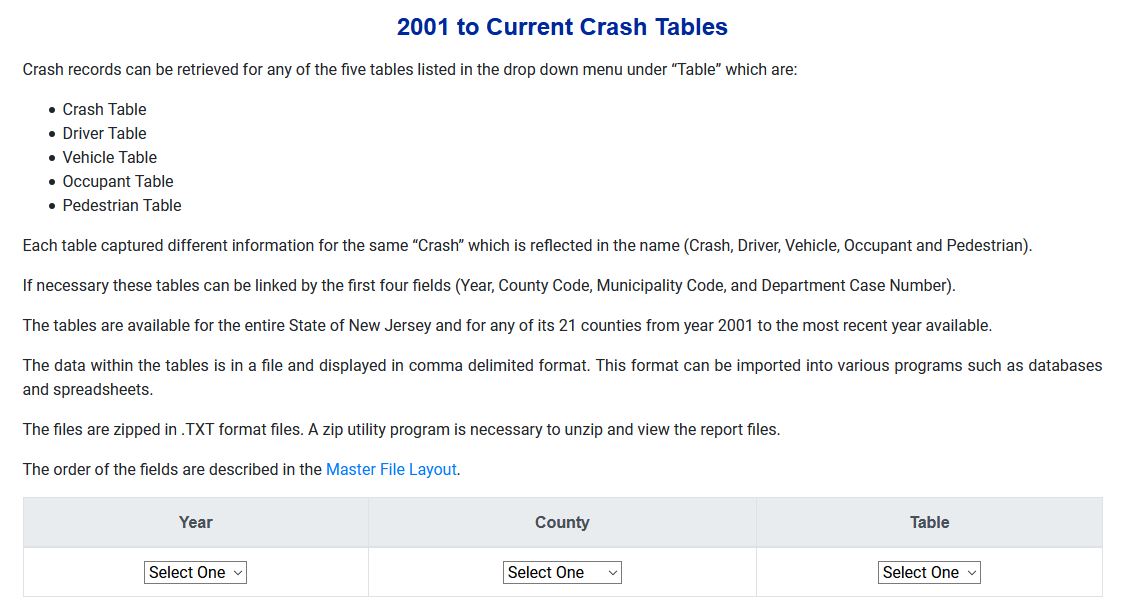
To download a table of data you must select the year, county and table and then download the data using your web browser. If you don’t select all 3 tables the site will throw an error. Given that the state currently publishes over 18 years worth of data across these 5 tables, this could result in a lot of pointing and clicking and manual effort. Scripting the download process in R would make this quite a bit easier, hence the rationale for njtr1.
Using njtr1 to download crash data
Fortunately, njtr1 make it possible eliminate such manual drudgery and begin immediately working with hundreds of thousands of points of data regarding crashes that occured on New Jersey’s highway.
Rather than manually hunting around for download links, the package makes it dead simple to start working with New Jersey crash data in R like so:
library(njtr1)
# Get crash data for the year 2019
get_njtr1(year = 2019, type = "Accidents")
# Get vehicle data for the year 2019
get_njtr1(year = 2019, type = "Vehicles")
# Get driver data for the year 2019
get_njtr1(year = 2019, type = "Drivers")
# Get occupant data for the year 2019
get_njtr1(year = 2019, type = "Occupants")
# Get pedestrian data for the year 2019
get_njtr1(year = 2019, type = "Pedestrians")
I used the year 2019 in the above example calls to the package’s function for downloading data because NJDOT has yet to release the crash tables for 2020, so 2019 is the latest available data at this point.
Each of these examples will return a tibble with the data for the specified table, suitable for additional analysis and integration in data science / transportation planning & research projects.
Conclusion & future plans
This is certainly not the first R package that has facilitated the download of data like this from transportation authorities into R. Probably the best known in this realm is the excellent stats19 package covering the U.K. by Robin Lovelace. njtr1 follows a similar vision and is the first of its kind that implements this type of tool for New Jersey. More work needs to be done to make this feature complete, but I feel this is a good starting point as the core tables can be downloaded.
Due to a schema change in 2017, the package currently only supports downloading these data from the years 2017 to present. A future update will implement the older schema that covers data from 2001 - 2016.
The source code can be found on GitHub. Documentation is here.
Gavin Rozzi
Pushing the boundaries of data, technology & public policy
Gavin Rozzi is a data scientist from New Jersey with expertise in leveraging public sector datasets, spatial data & mapping and emerging technologies to inform public policy development.